it's how you deliver
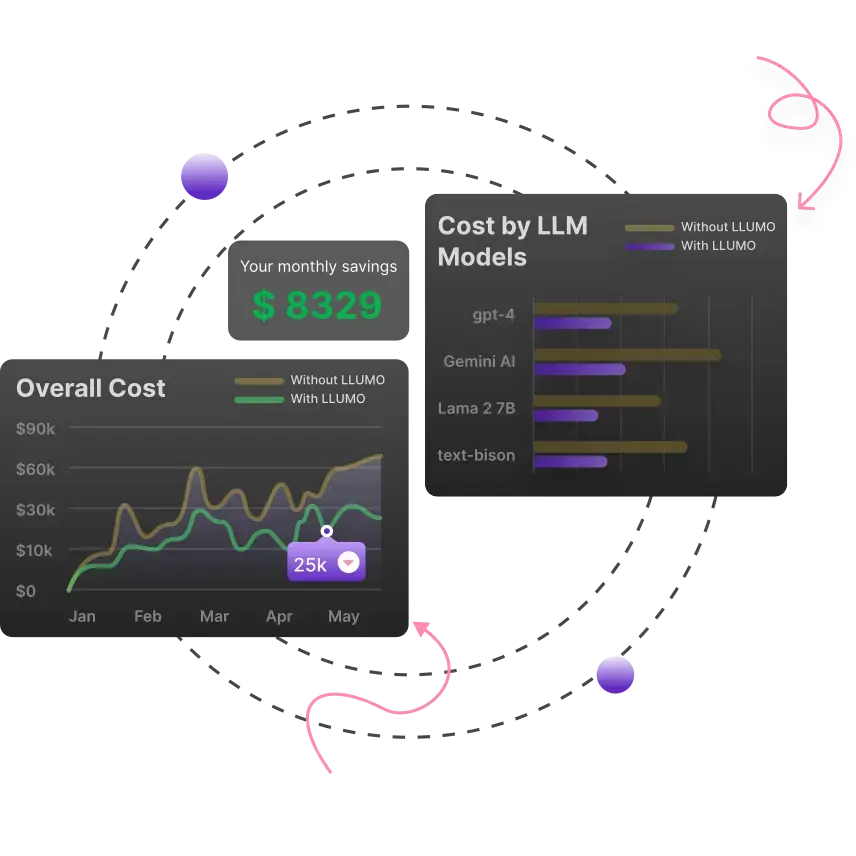
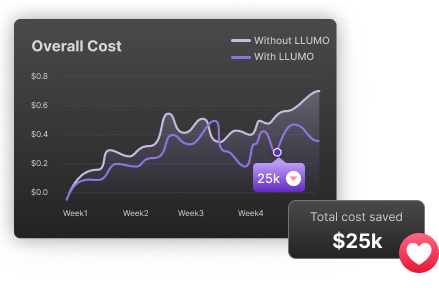
Cut 80% AI cost,
effortlessly
We compress tokens & AI workflows. Plug-in and watch LLM costs drop 80% with 10x faster inference

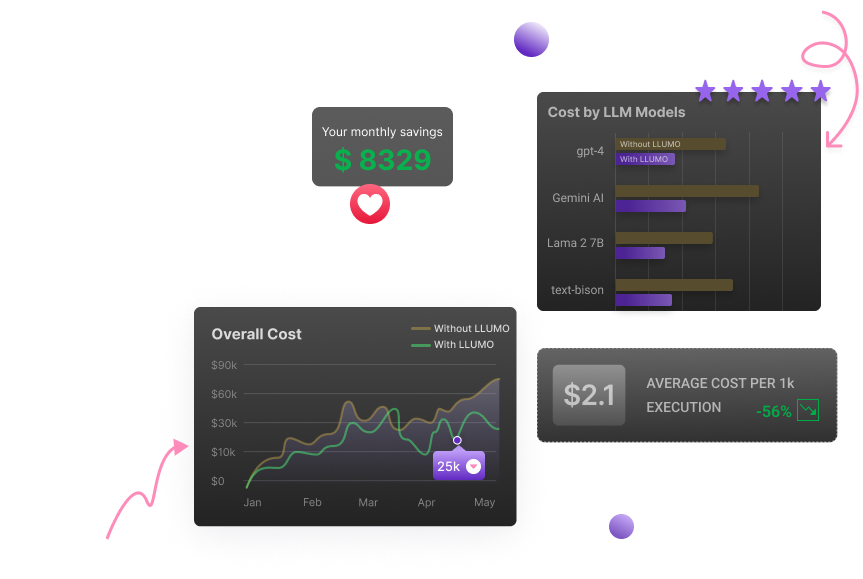
The best part is it reduces costs across all LLMs with just plug-and-play






How can LLUMO help you?

Cost Saving
Compress your tokens to build production-ready AI at 80% cost and 10x speed


LLM Evaluation
Customize LLMs evaluation to gain 360° insights into your AI output quality
Why llumo ai?

Cut AI Cost
Compressed prompt & output tokens, to cut your AI cost with
augmented production level AI quality output

Cutting-edge Memory Management
Efficient chat memory management slashes inference costs
and accelerates speed by 10x on recurring queries.

Monitor AI performance
Monitor your AI performance and cost in real-time
to continuously optimize your AI product.
Best AI output quality in


Why LLUMO AI?
0X
Faster LLM Optimization
0%
Cost reduction
0%
Fewer hallucinations
0%
Shorter time to market
Testimonials
Don't take our word for it
Easy to integrate
We recently started using LLUMO. Initially, we were a bit skeptical that it will be hectic to integrate, but LLUMO support team made it super easy for us. The automated evaluation feature is another standout—it enables our team to test and enhance LLM performance at 10x the speed.
My AI team loves it
LLUMO has been a game-changer for our AI team. It not only helps us keep our LLM costs in check, but we’ve also seen a significant reduction in hallucinations thanks to their effective prompt compression. It is a key part of our AI workflow now.
It’s amazing
After implementing the RAG pipeline, our costs skyrocketed. A friend recommended trying LLUMO, and it completely changed the game. It significantly slashed our LLM bills and delivered faster inference. We couldn't be happier with the results.
Incredible Cost Savings and Performance
We were struggling with skyrocketing costs for our LLM projects. After switching, we not only cut our spend in half but saw a huge improvement in performance. The hallucinations are almost non-existent now, and our inference speeds are much faster.
Faster Time to Market with Superior Results
Our team was able to bring our AI product to market weeks ahead of schedule thanks to the LLUMO playground that enabled us to iterate prompts quickly. It helped us to reduce hallucination rate, totally a game-changer for the accuracy of our chat assistant
A must have LLMOps tool
We've tried several LLMOps tools, but this one has been the most reliable by far. Our costs are way down, and the performance is top-notch. Fewer hallucinations and faster iterations made our AI development much smoother
Learn key LLM hacks from the top 1% of AI engineers





Frequently Asked Questions

General
Get Started
Security
Billing